


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Watanabe, Seiya*; Kawahara, Jun*; Aoki, Takayuki*; Sugihara, Kenta; Takase, Shinsuke*; Moriguchi, Shuji*; Hashimoto, Hirotada*
Engineering Applications of Computational Fluid Mechanics, 17(1), p.2211143_1 - 2211143_23, 2023/00
Times Cited Count:1 Percentile:61.52(Engineering, Multidisciplinary)In tsunami inundations or slope disasters of heavy rain, a lot of floating debris or driftwood logs are included in the flows. The damage to structures from solid body impacts is more severe than the damage from the water pressure. In order to study free-surface flows that include floating debris, developing a high-accurate simulation code of free-surface flows with high performance for large-scale computations is desired. We propose the single-phase free-surface flow model based on the cumulant lattice Boltzmann method coupled with a particle-based rigid body simulation. The discrete element method calculates the contact interaction between solids. An octree-based AMR (Adaptive Mesh Refinement) method is introduced to improve computational accuracy and time-to-solution. High-resolution grids are assigned near the free surfaces and solid boundaries. We conducted two kinds of tsunami flow experiments in the 15 and 70 m water tanks at Hachinohe Institute of Technology and Kobe University to validate the accuracy of the proposed model. The simulation results have shown good agreement with the experiments for the drifting speed, the number of trapped wood pieces, and the stacked angles.
Hasegawa, Yuta; Aoki, Takayuki*; Kobayashi, Hiromichi*; Idomura, Yasuhiro; Onodera, Naoyuki
Parallel Computing, 108, p.102851_1 - 102851_12, 2021/12
Times Cited Count:2 Percentile:32.94(Computer Science, Theory & Methods)The aerodynamics simulation code based on the lattice Boltzmann method (LBM) using forest-of-octrees-based block-structured local mesh refinement (LMR) was implemented, and its performance was evaluated on GPU-based supercomputers. We found that the conventional Space-Filling-Curve-based (SFC) domain partitioning algorithm results in costly halo communication in our aerodynamics simulations. Our new tree cutting approach improved the locality and the topology of the partitioned sub-domains and reduced the communication cost to one-third or one-fourth of the original SFC approach. In the strong scaling test, the code achieved maximum 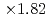 speedup at the performance of 2207 MLUPS (mega- lattice update per second) on 128 GPUs. In the weak scaling test, the code achieved 9620 MLUPS at 128 GPUs with 4.473 billion grid points, while the parallel efficiency was 93.4% from 8 to 128 GPUs.
speedup at the performance of 2207 MLUPS (mega- lattice update per second) on 128 GPUs. In the weak scaling test, the code achieved 9620 MLUPS at 128 GPUs with 4.473 billion grid points, while the parallel efficiency was 93.4% from 8 to 128 GPUs.
Asahi, Yuichi; Hatayama, Sora*; Shimokawabe, Takashi*; Onodera, Naoyuki; Hasegawa, Yuta; Idomura, Yasuhiro
Proceedings of 2021 IEEE International Conference on Cluster Computing (IEEE Cluster 2021) (Internet), p.686 - 691, 2021/10
Times Cited Count:2 Percentile:72.38(Computer Science, Hardware & Architecture)We develop a convolutional neural network model to predict the multi-resolution steady flow. Based on the state-of-the-art image-to-image translation model pix2pixHD, our model can predict the high resolution flow field from the set of patched signed distance functions. By patching the high resolution data, the memory requirements in our model is suppressed compared to pix2pixHD.
Murata, Isao; Yamashita, Kiyonobu; Maruyama, So; Shindo, Ryuichi; Fujimoto, Nozomu; Sudo, Yukio; Nakata, Tetsuo*
Journal of Nuclear Science and Technology, 31(1), p.62 - 72, 1994/01
Times Cited Count:3 Percentile:35.79(Nuclear Science & Technology)no abstracts in English
Kugo, Teruhiko; Nakakawa, Masayuki;
JAERI-M 92-117, 70 Pages, 1992/08
no abstracts in English
Murata, Isao; Yamashita, Kiyonobu; Maruyama, So; Shindo, Ryuichi; Fujimoto, Nozomu; Sudo, Yukio; Nakata, Tetsuo*
Proc. of the 1st JSME/ASME Joint Int. Conf. on Nuclear Engineering,Vol. 1, p.413 - 418, 1991/00
no abstracts in English
Onodera, Naoyuki; Idomura, Yasuhiro
no journal, ,
A real-time simulation of the environmental dynamics of radioactive substances is very important from the view-point of nuclear security. Since a lot of tall buildings and complex structures make the air flow turbulent in urban cities, large-scale CFD simulations are needed. To this end, a CFD code based on a Lattice Boltzmann Method (LBM) with a block-based Adaptive Mesh Refinement (AMR) method is developed. As the conventional LBM based on a single relaxation time collision operator often becomes numerically unstable at high Reynolds number, we apply a cumulant collision operator. The code is validated against a wind tunnel test, which was released from the National Institute of Advanced Industrial Science and Technology. The computational grids are subdivided by the AMR method, and the total number of grid points is reduced to less than 10% compared to the finest mesh. In spite of the fewer grid points, the turbulent statistics are in good agreement with the experiment data.
Hasegawa, Yuta; Onodera, Naoyuki; Idomura, Yasuhiro
no journal, ,
To reduce memory usage and accelerate data communication in the locally-refined lattice Boltzmann code, we tried an intra-node multi-GPU implementation using Unified Memory in CUDA. In the microbenchmark test with uniform mesh, we achieved 96.4% and 94.6% parallel efficiency on weak and strong scaling of a 3D diffusion problem, and 99.3% and 56.5% parallel efficiency on weak and strong scaling of a D3Q27 lattice Boltzmann problem, respectively. In the locally mesh-refined lattice Boltzmann code, the present method could reduce memory usage by 25.5% from the Flat MPI implementation. However, this code showed only 9.0% parallel efficiency on strong scaling, which was worse than that on the Flat MPI implementation.
Hasegawa, Yuta; Aoki, Takayuki*; Kobayashi, Hiromichi*; Idomura, Yasuhiro; Onodera, Naoyuki
no journal, ,
We developed a block-structured static adaptive mesh refinement (AMR) CFD code for the aerodynamics simulation using the lattice Boltzmann method on GPU supercomputers. The data structure of AMR was based on the forest-of-octrees, and the domain partitioning algorithm was based on space-filling curves (SFCs). To reduce the halo data communication, we introduced the tree cutting approach, which divided the global domains with a few octrees into small sub-domains with many octrees, leading to a hierarchical domain partitioning approach with the coarse structured block and the fine SFC partitioning in each block. The tree cutting improved the locality of the sub-divided domain, and reduced both the amount of communication data and the number of connections of the halo communication. In the strong scaling test on the Tesla V100 GPU supercomputer, the tree cutting approach showed 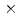 1.82 speedup at the performance of 2207 MLUPS (mega-lattice update per second) on 128 GPUs.
1.82 speedup at the performance of 2207 MLUPS (mega-lattice update per second) on 128 GPUs.
Onodera, Naoyuki; Idomura, Yasuhiro; Hasegawa, Yuta; Nakayama, Hiromasa; Shimokawabe, Takashi*; Aoki, Takayuki*
no journal, ,
This paper presents a novel data assimilation method in realistic turbulent boundary layer simulations for the realization of a wind digital twin. We have developed a plume dispersion simulation code named CityLBM based on a lattice Boltzmann method. CityLBM enables a real time ensemble simulation for several km square area by applying locally mesh-refinement method on GPU supercomputers. Mesoscale wind boundary conditions produced by a Weather Research and Forecasting Model are given as boundary conditions in CityLBM by using a nudging data assimilation method. In this study, we propose a dynamic nudging data assimilation method, where a particle filter optimizes the nudging coefficient based on the observation data. This approach gave reasonable agreements in vertical profiles of the wind speed, the wind direction, and the turbulent intensity compared to the observation data throughout the day, and enabled all-day simulations, where atmospheric conditions change significantly.
Matsushita, Kentaro; Ezure, Toshiki; Fujisaki, Tatsuya*; Imai, Yasutomo*; Tanaka, Masaaki
no journal, ,
Development of evaluation method for cover gas entrainment (GE) by vortices generated at free surface in upper plenum of sodium-cooled fast reactor (SFR) is required. An evaluation method by predicting vortices from flow velocity distribution obtained by 3D CFD analysis is developed, and partial refinement of analysis mesh from the viewpoint of improving efficiency of 3D CFD analysis is examined. In this study, a method of predicting vortex radius that can occur in a system by machine learning and using the predicted value as a reference value for analysis mesh before applying refinement (initial mesh). CFD analysis was performed for cylinder column system where wake vortex occurs by changing parameters such as cylinder diameter and inlet flow velocity, and supervised learning was performed using the obtained variables and vortex radius was predicted. As a result, it was obtained that initial mesh size can be efficiently determined by using the predicted vortex radius as a reference.

